- 저자 : Minh-Thang Luong Hieu Pham Christopher D. Manning
- 링크 : Arxiv.1508.04025
CS 224n으로도 유명한 Manning 교수가 이끌고 있는 Stanford NLP group에서 작성한 논문이다. 이 논문에 제시한 Neural Machine Translation (이하 NMT) 모델은 Attention Mechanism 기반의 모델로서 당시 몇몇 Task에서 State-of-the-art를 보여주는 놀라운 성과를 보여주었다. 다른 분야에서 각광받던 Attention Mechanism을 저자의 말에 따르면 NMT에 처음으로 적용한 사례였고 놀라운 결과와 분석을 통하여 NMT에서의 Attention Mechanism의 시작을 알렸다고 할 수 있을 것 같다.
Basic Idea
우선, NMT에 대해서 잠깐 짚고 넘어가자. 그동안 많이 봤듯이, NMT에 있어서 가장 널리 쓰이는 Sequence to Sequence의 기본적인 구조는 다음 Figure와 같으며 주요 계산은 다음 3단계로 구분할 수 있다.
- Encoder에서 Source sequence를 차례대로 계산
- 한 Input Sequence에 대한 Context vector를 계산
- Decoder에서 이를 바탕으로 Target sequence를 계산
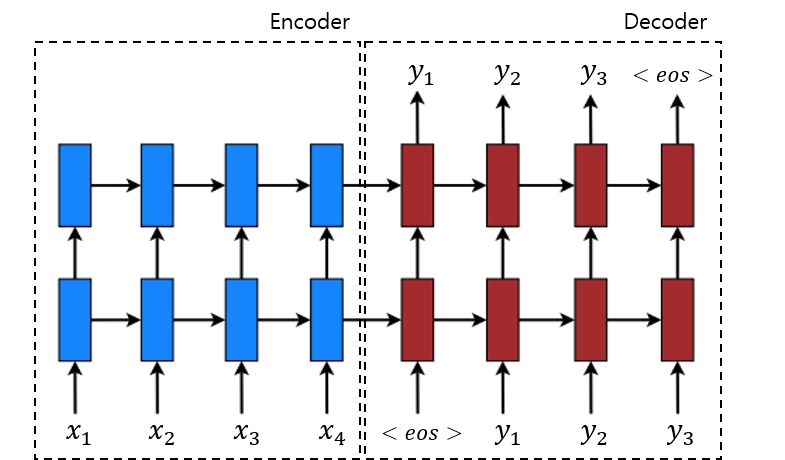
Context vector는 Source sequence의 정보를 하나의 vector에 담고 있는 것으로 볼 수 있는데 이는 그동안의 모델에서는 Decoder의 첫 hidden state를 계산할 때만 사용되었다. 이 접근 방식은 구조를 간단하게 만들 수는 있지만 Source와 Target의 관련성을 이용하는 Alignment 측면에서는 몇가지 문제점이 생각된다. 먼저, Context vector를 처음에만 사용하기에 나중 Target symbol을 계산함에 있어서는 충분히 정보가 반영되지 않을 수 있다. 그리고 무엇보다 Source와 Target의 관계는 symbol마다 다르기 때문에 고정된 Context vector를 사용하는 것은 제대로된 context를 전달해주지 못할 수 있다.
이러한 문제들을 해결하는 것이 Attention Mechanism인데 저자들은 이를 적용하기 위해 LSTM으로 Encoder Decoder를 구성하고 Decoder에서 target symbol을 계산하기 위해 각 Decoder의 hidden state와 함께 현재 target과 관련된 정보들을 충분히 담고 있는 context vector를 계산하여 사용했다. 이는 계산량은 늘었을지는 몰라도 Decoder에서 각 state에 맞는 source sentence의 정보를 반영할 수 있는 해결책이었다. 다음 수식을 통해 조금 더 자세히 살펴보자.
$$\tilde{h}_t=\text{tanh}(W_c[c_t;h_t])$$ $$p(y_t|y_{\lt t}, x)=\text{softmax}(W_s\tilde{h}_t)$$ $$\begin{cases} c_t &: \text{context vector at time t} \\ h_t &: \text{hidden state in decoder at time t} \\ \tilde{h}_t &: \text{attentional vector at time t} \\ \end{cases}$$
수식에서는 딱 한 가지만 주목하면 되는데, 를 계산할 때 각 state에 따라 다른 context vector를 사용한다는 점이다. 이 차이점은 Target symbol들과 Source symbol들간의 alignment를 적용할 수 있게 해주었으며 충분히 Source의 context를 전달할 수 있게 해주었다. 이 아이디어를 기반으로 하여 제시된 모델은 총 2가지로 각각은 context vector를 계산할 때 어느정도 범위의 Source sentence를 사용하는지에 있어 차이를 보인다.
- Global Attention : 모든 Source 단어들을 고려한다.
- Local Attention : 특정 영역의 한정된 숫자의 단어들을 고려한다.
Global Attention
Global Attention은 특정 target symbol과 source와의 alignment를 계산함에 있어 다음 Figure에서 볼 수 있듯이 전체 source를 사용한다. alignment되는 정도는 다음의 식을 통해 계산되는데, 저자들은 가장 기본적인 location 방법 이외에 총 3가지의 방법을 이용하여 score를 계산하였다.
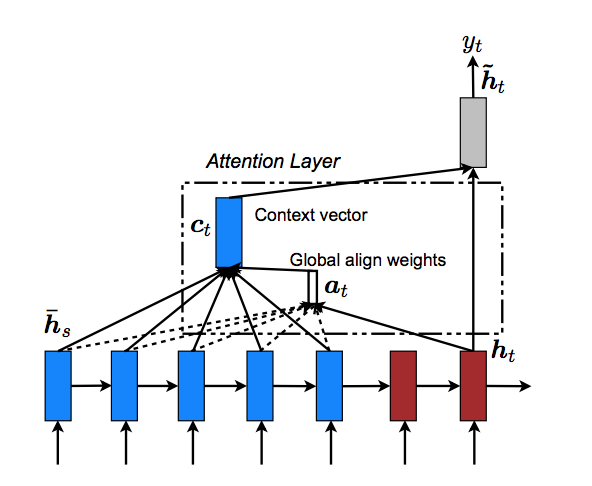
$$a_t(s)=\text{align}(h_t,\bar{h}_s)= \frac{\exp{(\text{score}(h_t,\bar{h}_s)})}{\Sigma_{s^{'}}\exp{(\text{score}(h_t,\bar{h}_{s^{'}})})}$$ $$\text{score}(h_t,\bar{h}_s)=\begin{cases} h_t^{\intercal}\bar{h}_s & \text{dot} \\ h_t^{\intercal}W_a\bar{h}_s & \text{general} \\ W_a[h_t^{\intercal};\bar{h}_s] & \text{dot} \\ \end{cases}$$ $$a_t = \text{softmax}(W_ah_t) \text{: location}$$
여기서 얻어지는 alignment vector는 후에 context vector 를 계산하기 위해서 source의 각 hidden state 에 대한 weighted factor로 적용된다. 즉, 현재 target에 대한 average context로 볼 수 있겠다.
저자가 추가적으로 언급하였듯이 이 모델과 2015년 Bahdanau가 제시한 모델과 비슷해보일 수 있지만, Bahdanau보다 간단히 top layer의 hidden state를 사용하였으며 이전 hidden state가 아니라 현재 hidden state를 사용하여 보다 간단하고 일반화되어있다는 점에서 차별화를 둘 수 있겠다.
Local Attention
Global Attention는 항상 Source 전체를 계산해야하기 때문에 Paragraph와 같이 깉 문서일 수록 Compuational Cost가 커진다. 이를 해결하기 위해서 제시된 두번째 모델 Local Attention은 다음 Figure처럼 Source의 일부분만을 이용하여 alignment를 계산한다. 이는 Xu가 제안한 soft and hard attention으로부터 영향을 받은 것으로 alignment position을 계산하여 주변 값만을 사용한다.
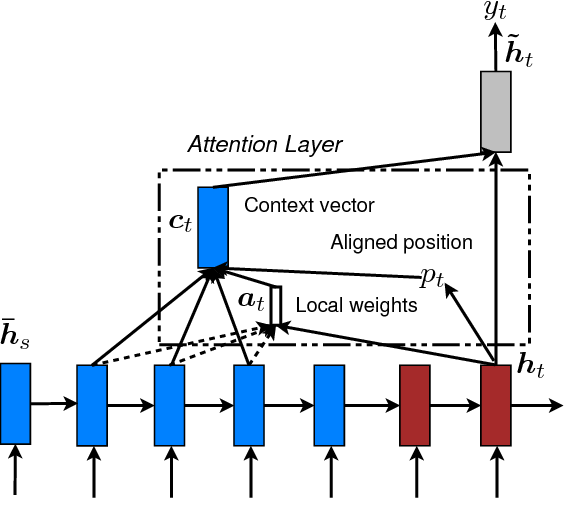
alignment position을 계산하기 위해서 저자는 2가지 방법을 제시하였다. 첫번째는 monotonic alignment로 source와 target 단어의 순서가 비슷하다고 보는 것이며, 두번째는 predictive alignment로 다음의 식을 통해서 계산한다. sigmoid의 결과값은 항상 0~1이므로 alignment point가 0~S임을 알 수 있다.
$$p_t=S\cdot \text{sigmoid}(v_p^{\intercal}\tanh(W_ph_t))$$ $$\begin{cases} W_p, v_p &: \text{parameter of prediction to be trained} \\ S &: \text{Source sentence length} \\ \end{cases}$$
위에서 구한 alignment point를 기준으로 alignment vector를 계산하는데, 이는 global attention 때와 같은 align 함수에 point를 중심으로 주변의 gaussian distribution을 곱해서 구해낸다. 이 접근 방법은 좋은 성능을 보여주었던 2015년 Gregordml 모델이 image generation에서 사용한 target을 중심으로 한 zoom과 비슷하게도 볼 수 있다.
Input-feeding Approach
마지막으로 저자가 사용한 테크닉은 다음 Figure처럼 attention layer를 encoder와 decoder에 걸쳐 적용하는 것이었다. 이 방법을 적용한 목적은 이전에 어떤 align이 된지에 대한 정보까지 뒤의 decoding 과정에 적용하는 것이며 또한 수평, 수직으로 길게 확장되는 네트워크를 만들기 위함이라고 한다. 심플하면서도 의도한 바를 적용하기 위한 좋은 방법으로 보인다.
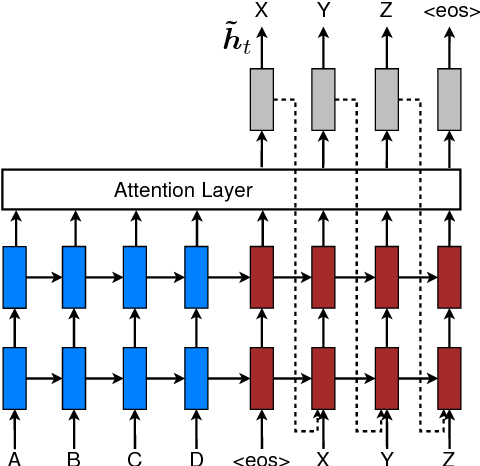
Experimental Setup
- Dataset : WMT English-German을 사용하였으며 newstest2013이 development set으로 사용되었다. 각 언어에서 빈번하게 사용되는 50,000개의 단어를 사용하였고, 여기 포함되지 않은 단어들은 [UNK] Token 처리되었다.
Result
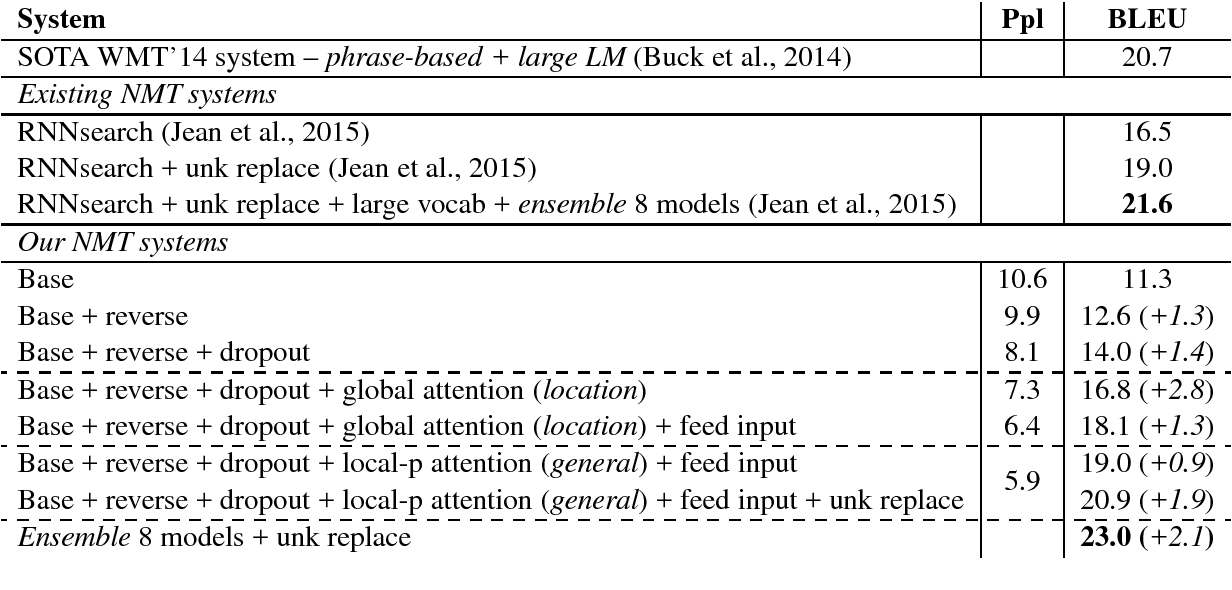
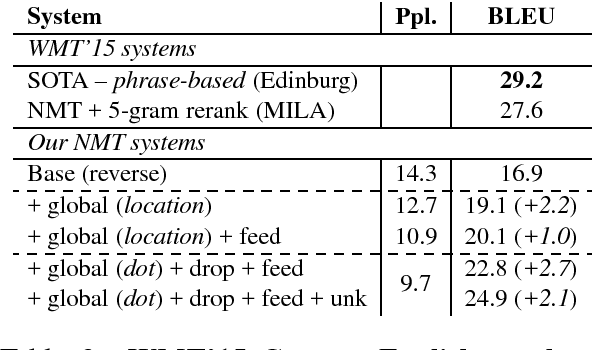
결과 비교는 WMT ‘14와 WMT ‘15를 사용하였는데, 결과가 굉장히 인상적이다. WMT ‘14, WMT ‘15 English to German에서는 Best result가 기존 SOTA system을 능가하는 모습을 보여주었고 Attention을 포함한 여러 가지 테크닉을 하나씩 적용함에 따라 증가하는 점수들을 일일히 보여주고 있다. (첫번째 표는 WMT’14, 두번째 표는 WMT’15이다.)

WMT ‘15 German to English에서는 기존 SOTA만큼은 아니지만 그 만큼의 점수를 보여주었다.
결과를 비교하는 것 이외에도 저자는 newstest2014를 이용한 Learning Curve 분석, Long sentence에 대한 BLEU, Attentional Architecture 그리고 Alignment quality에 대한 분석을 수행하였다.
Conclusion
이 논문에서 저자는 기존의 Attention Mechanism을 적용한 2가지 종류의 모델을 제시하였으며 그 결과는 기존 SOTA를 능가하거나 근접하여 굉장히 성공적이었다. 전체 Source sentence를 참고하는 global attention과 일부분을 보는 local attention 중 결과적으로 local attention이 더 좋은 성능을 보여주었는데, 이는 전체 sentence를 계산할 때 source에서 중요한 부분이 상대적으로 덜 반영됬기 때문으로 생각된다. 성공적인 결과 외에도 Attention을 포함한 technique을 세세하게 분석한 내용은 앞으로 연구를 진행함에 있어서 참고할 만한 좋은 방향으로 생각된다.