- 저자 : Ashish Vaswani를 포함한 Google Brain, Google Research
- 링크 : Arxiv.1706.03762
이 논문은 NLP에 있어서 한 획을 그었다고 말할 수 있는 논문이다. 저자는 그동안 당연시 여겨졌던 RNN과 같은 Sequential 구조에서 벗어나 오로지 Attention Mechanism만을 사용한 구조를 통해 빠른 학습 속도와 SOTA 성능을 보여주었다. 논문을 읽고 나면 Attention is all you need라는 논문의 제목이 정말 잘 지은 것이라고 생각하게 될 것이다.
1. Main Idea
한동안 NLP에 있어 RNN 기반의 모델은 항상 주류를 이루었다. LSTM이나 GRU와 같은 모델들이 등장하였고, Attention Mechanism을 사용하여 성능을 향상시켜왔었지만 모두 다 RNN Encoder-Decoder를 기반으로 하고 있었다. 물론 이밖에도 CNN을 기반으로 한 모델들도 좋은 성능을 보여주었었으나 각각은 다음과 같은 문제점들을 가지고 있었다.
- RNN
- Sentence의 symbol들을 따라 계산을 진행하기 때문에 길이에 비례하여 계산량 증가
- 각각의 단계(Layer)에서 hidden state를 계산하는 과정이 이전 계산값을 기반으로 하기 때문에 병렬화가 어려움
- CNN
- 보다 나은 병렬화가 가능하지만 일반적으로 RNN보다 kernel width만큼 더 계산량이 많음
- 공통
- 문장의 길이가 길어짐에 따라 Attention Mechanism에 대한 계산량이 많아짐
결국 주된 문제는 Sequential Computation에서 온다고 할 수 있다. 저자는 이를 해결하기 위해 Attention을 Encoder-Decoder 사이에만 적용하는 것이 아니라 Attention을 Encoder와 Decoder 내부에 Self-Attention의 개념으로 적용한 Transformer를 제시하였다. 이 모델은 다음과 같은 장점을 가지고 있다.
- Sentence에 대한 Sequential Computation을 사용하지 않아 병렬화 가능
- Input-Output에 대한 Global dependency를 상수 시간에 계산 가능
- 단 12시간, P100 GPU를 8개 사용하여 SOTA 달성
2. Model 구조
Transformer의 구조는 다음 Figure 1과 같이 이루어져 있다. Encoder와 Decoder는 Figure 1에 나타난 Layer가 stack되어 있는 구조이며 논문에서는 각각 6개의 Layer를 사용했다고 한다.
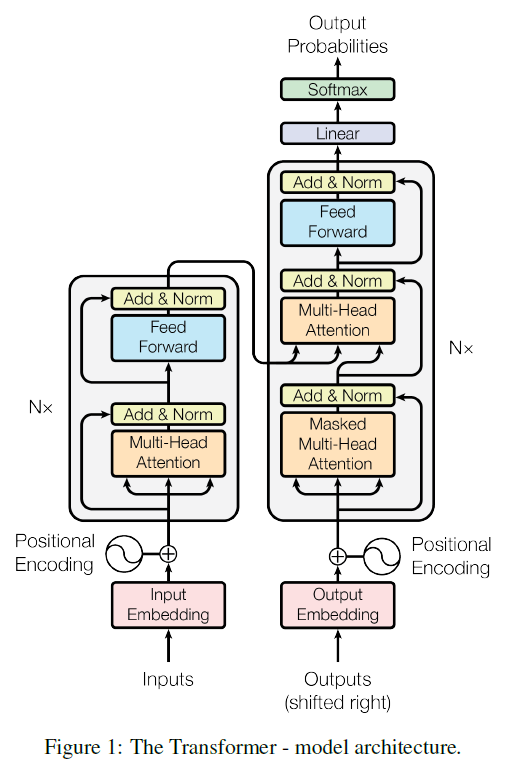
2.1 Encoder and Decoder stacks
Encoder
각 layer는 다음 2개의 part로 이루어져있으며 각각의 계산을 진행할 때는 Residual Connection과 Layer normalization을 적용한다.
- Multi-head attention
- Fully connected layer
Decoder
Encoder와 비슷하지만 RNN처럼 정보가 왼쪽에서 오른쪽으로만 전해질 수 있도록 한 Masked Multi-head attention이 추가되어있다.
- Masked Multi-head attention
- Multi-head attention
- Fully connected layer
2.2 Attention

Transformer에서의 attention은 먼저 Multi-head attention을 이루고 있는 Scaled Dot-product attention을 살펴보아야 한다. 크게 Attention에 사용되는 값은 3가지로 나눌 수 있는데, 각각은 Query(Q), Key(K), Value(V)이다. 이 3개의 값은 Encoder-Decoder의 각 부분에 따라 값이 달라지는데 계산 과정을 쉽게 생각해보면 다음과 같이 생각해볼 수 있다.
- Query는 단어 그대로 질의하는 입장으로 생각하자.
- Query가 들어오게 되면 Key값과의 계산을 통하여 기준 값 Key에 대한 Query의 상대적인 weight(softmax)를 계산한다.
- 이 Weight를 Value에 곱함으로써 Query와 Key의 연관성을 기준으로 한 새로운 값을 얻게 된다.
이 과정을 통해 Attention이 적용된 값을 얻을 수가 있는데, Transformer에서는 여기서 멈추지 않고 Scaled Dot-Product attention을 겹쳐놓은 Multi-Head attention을 사용하였다. Figure 2의 오른쪽을 보면 h개만큼 Scaled Dot-Product Attention이 사용된 것을 알 수 있다. 각각의 Attention에는 이전처럼 Query, Key, Value가 사용되었는데, 차이점은 이 세 값들을 바로 사용하는 것이 아니라 h개의 Attention각각에 대해서 다르게 초기화된 Parameter Matrix를 곱하여 (Projection) 사용한다. 이후, Scaled Dot-Product Attention을 통하여 h개의 다른 값들을 얻게 되고 이를 Concat하여 Attention 결과물을 얻게 된다.
h개의 다른 Parameter Matrix를 사용하여 Attention을 계산하기 때문에 Multi-head attention은 단 하나의 Scaled Dot-Product Attention을 사용할 때보다 주어진 Query, Key, Value에 대해서 보다 다양한 상황(subspace)에 대한 attention을 계산할 수 있게 된다. 이 Multi-head attention은 Transformer에서 크게 세 부분에 사용된다.
-
Encoder의 Multi-head attention
- Self attention에서의 Query, Key, Value는 모두 같은 Input값이다. 즉, Input으로 주어진 같은 문장의 요소간의 연관성(Attention)을 계산함으로써 말그대로 스스로에 대한 연관성(Self-attention)을 계산하는 것이다. 이 과정을 통하여 이전 RNN에서 hidden state를 통해 계산했던 context vector를 대체한다.
-
Decoder의 Masked multi-head attention
- Encoder와 비슷하게 Query, Key, Value로 같을 값을 사용하지만 여기서는 Masked가 추가되있음에 주목하자. Encoder와 달리 Decoder에서는 Input Sentence가 전부 주어지는 것이 아니라 하나의 Symbol씩 계산해나간다. 하지만, Transformer에서의 attention을 계산할 때는 하나의 sentence 전체를 한번에 계산하기 때문에 decoder의 경우 아직 계산되지 않은 Sentence 뒤쪽 값에 대한 attention이 포함될 수 있다. 이를 막기 위해 Mask 과정이 추가되었는데, 이는 Query와 Key값 과정 중 현재 계산 대상이 된 symbol 뒤의 값들을 모두 $-\inf$ 처리하여 weight 자체를 0으로 만들어버린다. 이 과정은 다르게 말하면 정보의 전달이 Sentence 뒤에서 앞이 아닌 무조건 앞에서 뒤로 흘러갈 수 있도록 설정했다고 할 수 있다.
-
Decoder의 Multi-head attention
- 여기서는 Query로 Decoder의 이전 Layer output값이 사용되며 Key, Value로 Encoder output layer의 값이 사용된다. 이전에 이야기한것처럼 Decoder의 계산되는 output에 Encoder에서 계산된 input sentence의 information이 적용되었다고 생각해볼 수도 있을 것이다.
저자가 이야기하는 기존 모델들과 비교해보았을 때, Self-attention이 같는 장점은 다음과 같으며 Table 1을 보면 보다 자세히 알 수 있다.
- Layer당 전체 계산량이 줄어든다.
- 계산이 병렬화될 수 있다.
- dependency를 계산할 때 필요한 Path length의 최대값이 상수이다. (RNN은 Sentence의 길이만큼 CNN은 Sentence의 길이의 kernel size로 log를 취한 값만큼 필요하다.)
- 이전 Sequential Computation Model들보다 Context vector를 구함에 있어 Dependency를 기반으로 하여 설명이 용이하다.

2.3 Position-wise Feed-Forward Networks
Encoder, Decoder의 각 layer 마지막에는 Fully connect network가 사용되는데, 여기서는 ReLU가 적용된 두번의 Linear transformation이 계산된다.
2.4 Embeddings and Softmax
다른 번역 모델처럼 Input, output token들에 대해 기존에 학습된 embedding을 사용하였고, 각각의 embedding layer는 공통된 weight matrix를 가지고 있다.
2.5 Positional Encoding
Attention에서 언급했던 것처럼 Transformer는 하나의 sentence를 한번에 계산하기 때문에 기본적으로 단어의 앞 뒤 순서 정보를 따로 가지고 있지 않다. 이를 위해 저자는 Positional Encoding을 Encoder, Decoder stack 각각에 사용하였는데, 먼저 Positional encoding을 계산하고 이를 input 값에 더하였다. Positional Encoding으로는 다음과 같이 이론화하기 쉽고 학습에 용이성을 가진 position에 따른 $\sin$, $\cos$모델을 사용하였다. (아래 식에서 $i$는 dimension $pos$는 sentence에서의 position을 의미한다.)
$$PE_{(pos,2i)}=\sin(pos/10000^{2i/d_{model}})$$ $$PE_{(pos,2i+1)}=\cos(pos/10000^{2i/d_{model}})$$
3. Conclusion
저자는 총 다음과 같이 3가지의 연구를 진행하였다.
-
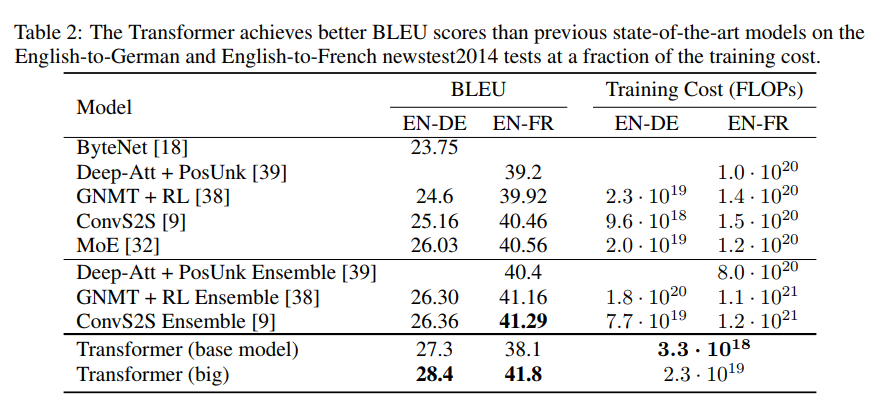
Transformer base Model과 big model을 사용한 WMT’14 En → Fr , En → De Data 학습
- Table 2와 같이 보다 짧은 시간에 적은 Training cost로 SOTA 달성
-
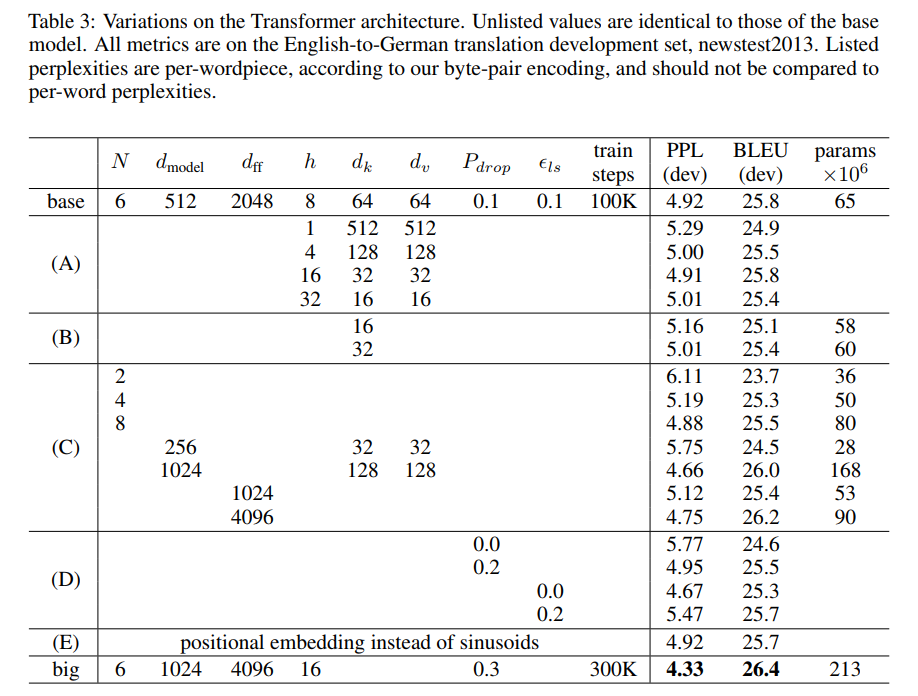
다음 Table3과 같이 Transformer의 구조 hyper parameter variation에 대한 성능, 복잡도 비교
-
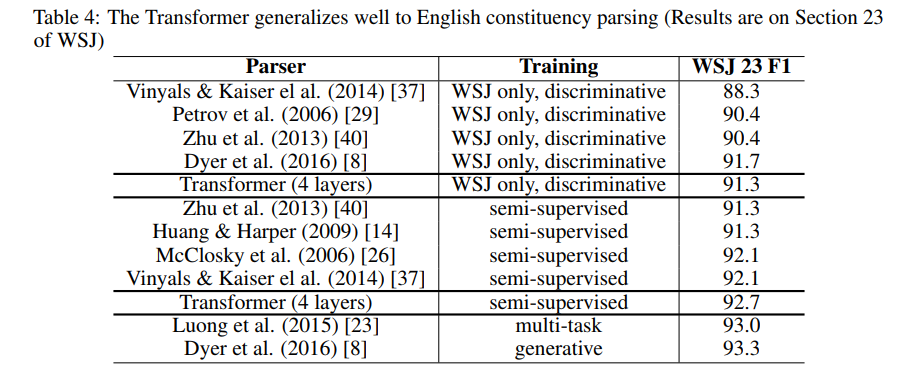
다음 Table4와 같이 작은 모델, 적은 데이터를 통한 English constituency (long sentence)에 대한 연구
4. Key points
- Attention을 모델의 일부분으로 사용한 것이 아니라 attention만을 사용한 첫 모델
- Self-attention을 통한 Input sentence에 대한 dependency 계산
- 기존 모델들 대비 훨씬 적은 계산량
- Sentence를 한 번에 계산하여 병렬 계산 가능
- 짧은 시간의 학습을 통하여 SOTA 달성