- 저자 : Yonghui Wu, Mike Schuster… (Google)
- 링크 : [Arxiv.1609.08144][https://arxiv.org/abs/1609.08144]
읽으면 읽어갈수록 역시 구글이라는 소리가 나오게 하는 논문이다. 당시 NMT의 문제점들을 먼저 명시하고 이를 어떻게 해결하였는지 아주 세세하게 설명을 해주고 있다. 비록 3년이 지난 논문이지만 NMT를 공부해가는 입장에서 많은 도움을 받을 수 있었다. 새롭게 NMT, Attention 관련 공부를 하는 상황이라면 이 논문을 제대로 읽어보는 것을 추천한다.
1. Main Idea
기존의 NMT는 큰 성공을 거두고 있었지만, Large Scale 시스템의 경우 정확도 측면에서 여러 어려움을 가지고 있었다. 저자가 제시한 주요 문제점 3가지는 다음과 같다.
- Training과 Inference에 있어서 너무 느리다.
- 빈도수가 적은 단어의 처리가 비효율적이다.
- 때때로 Source 문장 전체가 번역이 안될때가 있다.
실제로 당시 Google Translator과 같이 상용에 사용되고 있던 Large Scale 시스템들은 통계 기반 SMT의 대표격인 PBMT를 쓰고 있었다. 이러한 문제들을 해결하기 위해서 저자가 새롭게 제시한 방법 3가지는 다음과 같다.
- 속도 측면에서의 향상을 주기 위하여 parallelism과 quantization, TPU 사용
- Wordpiece model을 적용
- Length normalization과 coverage penalty를 decoder beam search 과정에 적용
이 밖에도 Residual Connection이나 강화학습 등을 적용하였는데, 새롭게 제시된 모델 GNMT는 기존의 문제들을 효과적으로 해결하여 점수를 향상시켰을 뿐만 아니라 기존 모델들 대비 Training, Inference 속도까지 향상시켰다.
2. Model 구조
기본적인 구조는 Encoder - Attention - Decoder로 이루어져있다. (Fig.1)
- Encoder : 8개의 LSTM (1 bi-direction + 7 uni-direction)
- Attention : 1 Hidden layer의 Feed Forward Neural Network
- Decoder : 8개의 LSTM (8 uni-direciton)
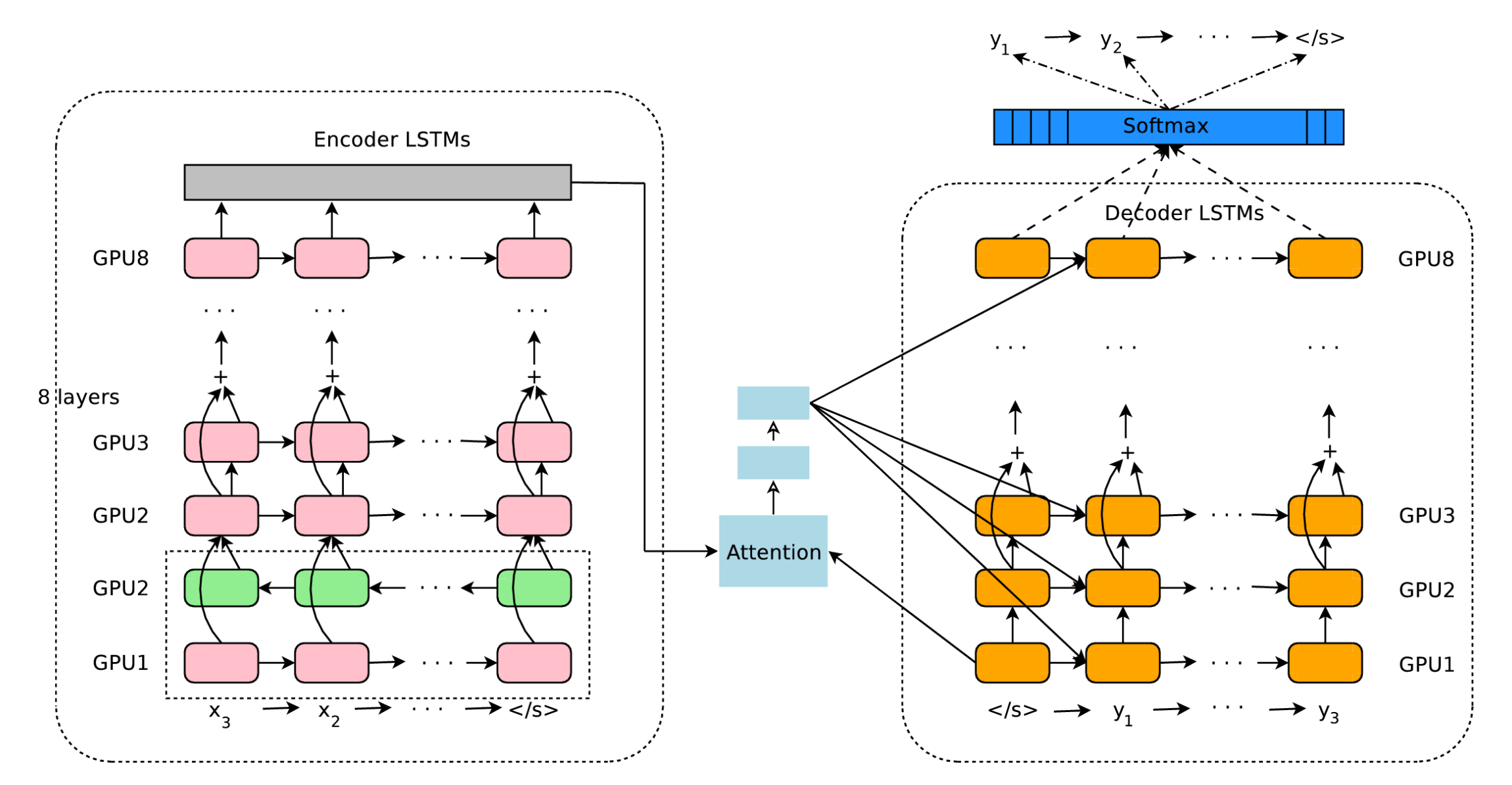
Residual Connection
통산 Deep LSTM이 Shallow LSTM보다 좋은 성능을 내는 것은 알려졌지만, 이를 학습시키는 과정에서는 Deep한 구조때문에 Vanishing or exploding gradient문제가 발생했었다. Residual connection은 이를 해결하기 위해 사용되었는데, LSTM의 Output을 다음 LSTM의 Input으로 사용하는 과정에서 추가적으로 이전 Input을 더하는 방법이다. (Fig.1의 Encoder part) 이를 통하여 Deep network에서의 gradient problem을 해결할 수 있었다고 한다.
Bi-directional Encoder for first layer
보통 Source sentence들을 Left → right의 방향성을 띄고 있기 때문에 Encoder에서는 이를 순서대로 계산해나가지만 language pair의 경우에 따라 target에 대한 information이 source에서 역순 또는 넓게 분포해있을 수도 있다. 이를 해결하기 위해서 한 방향으로만 계산하는 것이 아니라 양 방향으로 source sentence를 계산해나가는 bi-directional encoder를 사용하였다. (Fig.1의 Encoder의 첫번째 Layer) Bi-directional encoder는 Encoder의 첫번째 layer에만 사용되었는데, 그 이유는 최대한 parallelism을 반영하여 속도를 높이기 위함이었다.
Model parallelism
이 모델은 속도를 향상시키기 위해서 Model parallelism과 Data parallelism을 적용하였다.
- Data parallelism : 같은 모델의 parameter를 공유하는 n개의 모델 replica를 만들었으며 Downpour SGD algorithm를 사용하여 각각 학습해 나감과 동시에 각각의 replica와 비동기적으로 ADAM과 SGD algorithm을 이용하여 학습하였다.
- Model paralleism : 이 논문에서 사용한 모델은 첫번째 layer를 제외하고는 uni-direction이기 때문에 각각의 LSTM layer를 다른 GPU에서 계산하면 이전 layer의 계산이 끝나기 전에 다음 layer의 계산을 진행시킬 수 있었다. 첫번째 layer는 bi-direction이므로 2개의 GPU를 사용하여 계산을 먼저 진행시킨 후, 해당 Layer의 계산이 끝나면 나머지 Layer는 parallelize 하여 계산을 진행하였다. Attention을 적용하는 Decoder부분에 대해서도 비슷한 방법이 적용되었는데, 최대한 parallelism을 적용하기 위해서 첫번째 layer에 대해서만 계산을 하여 이 상수 값을 전체 layer에 대해서 적용하는 방법을 사용하였다.
3. Segmentation approach
처음에 언급한 것처럼 NMT가 가지고 있는 문제 중에 하나는 빈도수가 적은 단어들을 처리하기가 힘들다는 점이었다. 이러한 문제들을 translation of out-of-vocabulrary (OOV)라고 하며 이러한 문제점에 대한 해결책으로는 먼저 attention이나 추가적인 alignment model을 사용하여 Source의 단어를 그대로 copy하는 방법이 있으나 이는 언어에 대한 dependency가 있으며 네트워크가 deep해질수록 적용하기 어려운 문제점이 있다. 논문에서 사용된 방법은 이와 달리 sub-word unit을 사용하여 기존 단어들을 쪼개는 방식을 선택하였다.
Wordpiece Model
Wordpiece model은 구글 음성 인식 시스템에서 한국어/일본어 segmentation을 위해 만들었던 모델로 기존의 단어들을 작은 조각들로 나눌 수가 있다. 예를 들어, “나는 감자를 좋아합니다”와 같은 문장을 단어 기반으로 해석하는 것이 아니라 “ _나 는 _감자 를 _좋아 합니다” 와 같은 식으로 쪼개는 것이다. (실제 wordpiece를 적용한 결과는 다를 수 있습니다). 각각의 wordpiece로 나눌 때에는 앞에 “_”와 같은 기호를 사용하여 각각의 segment가 단어의 시작 부분임을 표시한다.
논문에서는 이를 적용하기 위해 먼저 기존 Source sentence에 wordpiece model을 적용하여 생성된 segments를 새로운 source setence로 encoder에 사용하였고, decoder에서는 얻어지는 단어들이 wordpiece일 것이기 때문에 이를 단어의 시작을 알려주는 “_”기호를 통하여 기존의 단어들로 바꾸어주었다. 뒤의 결과에서 나오지만 wordpiece를 적용한 결과 BLEU score가 좋아짐과 동시에 적은 빈도의 단어들에 대해서도 보다 robust한 결과를 얻을 수 있었다.
Mixed word / character model
Wordpiece model에서도 처리하기 힘든 OOV case들이 있는데, 이러한 문제들은 mixed word/character model을 사용하여 해결하였다. 보통은 OOV word들을 <UNK> 토큰으로 바꾸어 다루는 것과는 달리 각각의 character들을 나누어 관리하였는데 각각의 character에는 단어에서의 위치를 알려주고 일반적인 단어들과는 구별하기 위한 prefix을 사용하였다. 예를 들면, Miki라는 단어가 있을 때 이를 단어의 시작, 중간, 끝을 의미하는 <B><M><E> prefix를 붙여 <B>M <M>i <M>k <E>i 로 나누어 처리하였다. Decoder에서 이 prefix가 들어간 토큰이 들어간 결과물이 나온다면 이를 다시 이어붙이면 된다.
4. Training Criteria
일반적인 학습과정에서는 Maximum likelihood method를 사용하여 학습을 진행하지만 이는 BLEU score의 기준과는 다른 방식으로 학습이 진행될 여지가 잇다. 이 논문에서는 GLEU score를 이용한 강화학습을 이용하여 해결하고자 했다. GLEU score는 output, target sequence n-gram을 이용하여 recall, precision을 계산하고 두 값 중의 minimum을 계산한 값이다. 이들 실험에 따르면 이 방식은 보다 BLEU score metric에 가까우면서도 기존의 성능을 깍지 않았다고 한다. 이 새로운 방법을 적용하기 위해서 다음과 같은 순서로 학습을 진행했다고 한다.
- 기존의 Maximum likelihood method를 이용하여 학습을 진행
- 학습이 Convergence에 이르렀을 때, RL을 이용하여 학습을 추가적으로 진행
Quantizable Model and Quantized inference
NMT를 사용하고자 하는 상황에서 성능이 좋더라도 느린 속도와 큰 사이즈는 큰 어려움일수밖에 없다. 특히, 구글 번역기처럼 서비스를 하는 입장에서 속도적인 측면은 절대적으로 작용할 수 밖에 없다. GPU를 사용한 병렬화이외에도 속도를 향상시키기 위한 방법으로 사용된 것은 Quantization이었다. 이는 기존 모델의 parameter들이 32 비트 float 변수였다면 이를 8bit나 16bit로 낮추어 사용하는 방법이다.
이를 적용하기 위해서 Training 과정에서는 따로 quantization을 적용하지 않고 full-precision floating point를 사용하였지만 후에 quantization을 적용하는 변수들에 대해서 min, max의 constraint를 적용하였다. 결과에 따르면 constraint에 의한 악영향은 거의 없었으며 이를 통해 inference 과정에서 quantized variable을 사용 시에 성능적인 감소가 거의 없었다고 한다. Inferece과정에서 softmax와 attention model을 제외하고 대부분의 변수들은 8bit나 16bit로 quantize 되었다. 특히, 주목할 점은 이 방법론은 TPU에 최적화되어 아래의 표에서 볼 수 있듯이 기존 GPU를 사용한 방법 대비 다른 성능은 유지하면서 Decoding time은 거의 10분의 1로 줄인 모습을 확인할 수 있었다. 최적화된 Training, Inference를 위해 다음과 같은 순서로 연구를 진행하였다.
- Training : 먼저 GPU를 통해 학습을 진행하고 CPU를 사용하여 model decoding을 진행 (full resolution)
- Inference : TPU를 사용하여 decoding time을 최소화 (quantization)
5. Decoder
초반에 언급했던 NMT의 문제 중 하나는 문장이 길어질 수록 아예 잘못된 번역을 할 가능성이 높아진다는 것이었다. 이를 해결하기 위해 제시된 방법들은 coverage penalty와 length normalization이다.
- Coverage penalty : attention mechanism에 따라 source sentence를 보다 많이 cover하는 결과를 우선시하는 방법
- Length normalization : 문장의 길이를 계산 결과에 나누어주는 것으로 이는 짧은 문장 결과를 선호하는 beam search를 해결하는 방법
이 두 가지 방법들을 decoder에 적용하기 위해서 먼저 여러가지 상수들에 대해서 BLEU score를 계산하고 비교하여 그 중 가장 최선의 상수들을 선택하였다.
6. Conclusion
- Data : WMT’14 En -> Fr, En -> De, Large scale data testing용 Google 번역기 데이터
- Evaluation metric : multu-bleu score, 번역가들이 직접 번역 품질을 0부터 6까지 비교한 점수를 사용
실험 결과는 당시 SOTA를 얻었으며 번역 품질 면에서는 기존 구글 번역기에 사용되던 PBMT를 능가함은 물론 전문 번역가들이 번역한 점수에 근접하는 결과를 보여주었다. RL을 적용한 결과는 기존 대비 성능이 소폭 향상된 모습을 보여주었다.
7. Key points
- Deep Network 문제를 해결하기 위한 residual connection
- 속도적인 측면을 향상시키기 위한 parallelism, quantization
- Wordpiece model 사용
- Length normalization, coverage penalty 적용
- 번역 품질을 높이고자 새로운 Score인 GLEU 도입과 강화학습 사용
- CPU, GPU, TPU를 각각의 목적에 맞게 사용
- 번역 품질 비교를 위한 0~6 Score 사용