5년이나 지났지만 기초부터 다지자는 생각에 이 논문을 시작으로 NLP 관련 논문들을 부족하지만 리뷰해보고자 합니다. 틀린 내용에 대한 이야기는 언제든지 환영합니다.
- 저자 : Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio
- 링크 : Arxiv.1409.0473
이 논문 이전의 Machine Translation에서 쓰이던 방법들은 주로 Statistical Machine Translation였으며 Neural Network은 Main으로 쓰였다기 보다는 기존 System에 성능을 더하거나 결과를 Re-Rank하는 용도로 쓰였다. 그에 비해 이 논문에서 제안하는 System은 저자가 결론에서 언급한 것처럼 오로지 Neural Network만을 사용한 것으로 진정한 Neural Machine Translation의 시작이라고 할 수 있다.
한 가지 흥미로운 점이 하나 있었는데, Input sentence를 학습하는 과정에서 input word에 대한 attention 개념을 적용했다는 것이다. 현재 Attention을 기반으로 한 Transformer model이 점령한 세상에서 이 내용을 보니 감회가 새롭다.
Main Idea
논문에 사용된 Model 14년 Cho나 Sutskever가 언급했던, RNN Encoder-Decoder을 기반으로 하고 있다. RNN Encoder-Decoder는 Encoder에서 input sentence X를 차례대로 읽어나가 를 만들고 이를 Decoder에서 output sentence를 만드는 구조인데, Encoding 과정을 좀 더 자세하게 보면 다음 수식과 같다.
$$h_t = f(x_t, h_{t-1})$$ $$c = q({h_1, \cdots, h_{T_x}})$$ $$\begin{cases} h_t &: \text{hidden state at time t}\\ q &: \text{non linear function (like LSTM)} \end{cases}$$
Decoding 과정에서는 Encoder와 반대로 이전까지의 hidden state와 Encoder에서 얻은 context vector c를 이용하여 현재 단계의 단어를 예측하여 output을 만들어낸다. 이 과정을 자세히 살펴보면 다음 수식과 같다.
$$p(\bf{y}\rm) = \Pi^T_{t=1} p(y_t | {y_1, \cdots, y_{t_1}}, c)$$ $$p(y_t | {y_1, \cdots, y_{t_1}}, c) = g(y_{t_1}, s_t, c)$$ $$\begin{cases} \bf y\rm&: (y_1, \cdots, y_t)\\ g&: \text{non linear function} \\ s_t&: \text{hidden state at time t} \end{cases}$$
이렇게 Encoder-Decoder에 대해 대략적으로 살펴보았는데, 저자가 주목한 부분은 Encoder에서 Context Vector 를 만들어내는 부분이다. 저자는 고정된 길이의 vector에 Input Sentence 정보를 모두 다 담아내기에는 힘들어 길이가 길어질수록 Output Sentence에 대한 결과가 나쁘게 나올 것이라고 생각하였고 이에 대한 해결책으로 Alignment를 생각해냈다. 전체적인 구조는 다음 Figure와 같다.
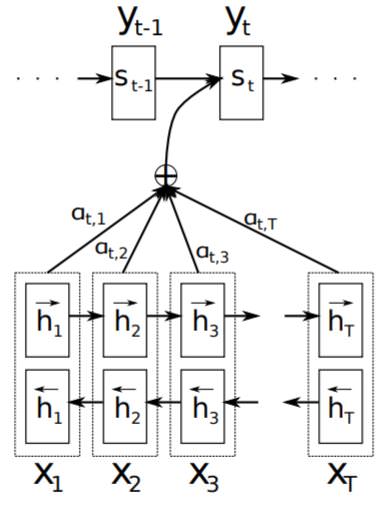
Alignment는 Output sentence의 단어가 Input sentence의 어느 부분에 주목해야 하는지에 대한 개념으로 이를 계산하기 위해서는 Encoder에서 context vector를 계산하기 위해 사용되고 버려지는 hidden state와 Decoder에서의 hidden state를 이용한다. 이는 Decoder에 사용되는 수식을 통해 보다 쉽게 이해할 수 있다.
$$p(y_t | {y_1, \cdots, y_{t_1}}, \bf{x}\rm) = g(y_{t_1}, s_i, c_i)$$ $$s_i = f(s_{i-1}, y_{i-1}, c_i)$$
기존의 Decoder와의 차이점은 각각의 output 단어에 대한 conditional probability를 계산함에 있어서 하나의 context vector를 사용하는 것이 아니라 각각 다른 context vector를 사용한다는 것이다. 이 context vector는 Encoder에서의 hidden state와 Decoder에서의 hidden state 그리고 weight를 곱하여 계산된다.
$$c_i = \Sigma^{T_x}_{j=1}\alpha_{ij}h_j$$ $$\alpha_{ij} = {\exp{e_{ij}} \above 1pt \Sigma^{T_x}_{k=1}\exp{e_{ik}}}$$ $$e_{ij} = a(s_{i-1}, h_j)$$ $$a : \text{alignment model}$$
여기서 사용되는 alignment model 는 하나의 feed forward neural network로 전체 system과 함께 학습되어 Soft alignment로서의 역활을 한다 (여기서 Soft의 의미는 단어와 단어가 1:1관계가 아니라 여러 단어에 걸쳐 관련이 있음을 말한다. 보다 자세한 건 뒤에서 나올 Graph를 보면 알 수 있다.).
저자는 Encoder에서의 hidden state를 annotation으로 context vector , 해당 단계에 대한 context vector를 expected annotation으로 보았다. 즉, 현재 output 단어에 대한 input sentence의 평균 alignment라고 생각해볼 수도 있을 것이다. expected annotation을 계산하는 데 있어서 사용된 weight는 굉장히 큰 의미를 가지고 있는데 input word가 output word에 대한 align될 확률, 정도로 볼 수 있으며 이는 자연스럽게 최근 사용되는 attention 개념과도 일치함을 알 수 있다.
마지막으로 RNN에서 가장 최근 단어가 focus되는 특징을 해결하고자 저자는 RNN의 계산을 정방향, 역방향으로 한 번씩 계산하여 concat하였고 이를 annotation을 계산할 때 사용하였다.
$$h_j = [\overrightarrow{h^T_j};\overleftarrow{h^T_j}]^T$$
Experimental Setup
-
Dataset : WMT ‘14 English-French를 사용하였으며 각 언어에서 빈번하게 사용되는 30,000개의 단어를 사용하였다. 여기 포함되지 않은 단어들은 [UNK] Token 처리되었다.
-
Model : 모델 비교를 위해 같은 데이터를 사용하여 기존 모델인 RNN Encoder-Decoder와 새로운 모델인 RNNsearch를 학습하였다. 각 모델을 두 번 학습하였는데 먼저는 Sentence의 단어 갯수가 30개까지만을 학습키고 (RNNencdec-30, RNNsearch-30)와 50개까지 학습시켰다 (RNNencdec-50, RNNsearch-50). Training은 80문장씩으로 이루어진 mini batch SGD를 사용하였다. 학습이 된 후에 prediction에서는 beam search를 사용하였다.
Result
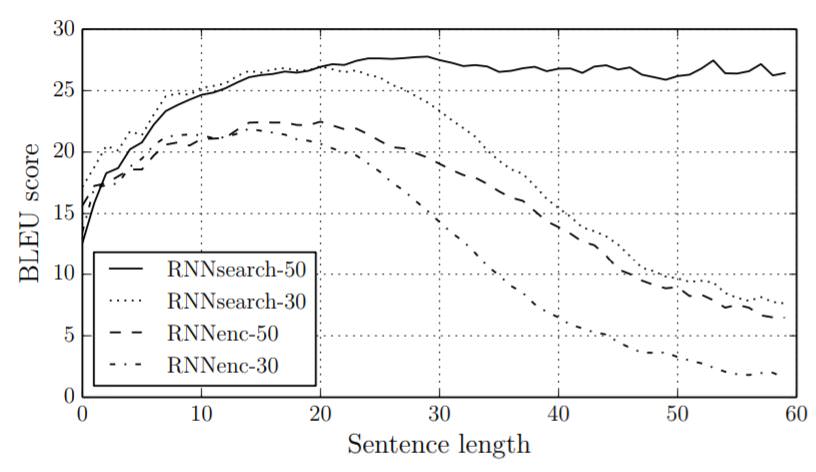
결과는 굉장히 성공적으로 나왔는데, 먼저 아래 그래프에서 볼 수 있듯이 RNNsearch가 BLEU Score에서 기존 모델을 능가하는 모습을 보여주었으며 특히 RNNsearch-50은 sentence가 길어지더라도 성능 저하가 일어나지 않는 모습을 확인할 수 있었다.
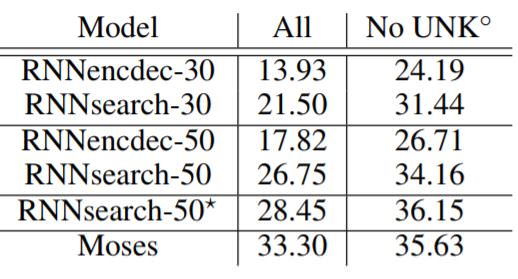
다음 표는 보다 자세한 BLEU Score 점수를 보여주는데, RNNsearch가 기존 모델을 능가하는 모습을 다시한번 확인할 수 있으며 특히, 더이상 성능이 증가하지 않을 때까지 학습시킨 RNNsearch-50*의 경우 기존 conventional phrase-based 번역 시스템인 Moses를 능가하는 모습을 확인할 수 있었다.
Alignment(Attention) 측면에서의 결과는 다음 Graph에서 확인할 수 있다. (검은색이 0, 흰색이 1을 의미) input 단어들에 대한 output 단어들의 alignment 2D graph인데 먼저 크게는 단어들이 거의 monotonic 관계를 이루고 있는 것을 볼 수 있다. 하지만, 이는 1대1관계만 있는 것이 아니라 몇몇 output 단어들은 여러 input 단어들에 걸쳐 align되어있는 soft alignment를 확인할 수 있다. 이를 통해 이 Model이 Decoder에서 output 단어를 계산할 때에 있어 특정 input 단어만을 보는 것이 아니라 그 앞 뒤로 여러 단어를 보고 문맥을 파악한다고 해석할 수도 있을 것이다.
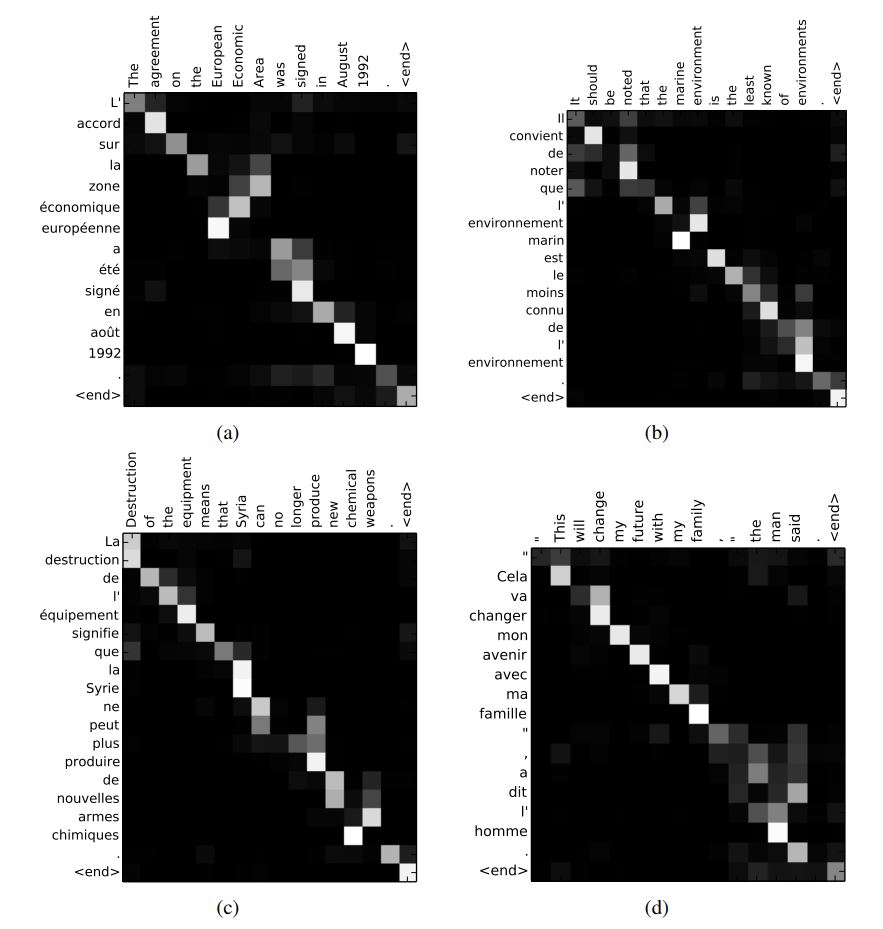
이 밖에도 Long Sentence에 대한 결과 분석이 있는데, 이 부분에 대해서는 어떤 프랑스어가 번역이 잘 된 것인지 잘 모르기 때문에 새로운 모델이 보다 Robust하다는 저자의 말을 그대로 따르도록 하겠다.
Conclusion
이 논문 이전 많은 논문들이 Neural Network를 Machine Translation에 사용하려고 했지만 이는 기존 Statistical Translation에 부수적으로 사용하는 것일 뿐, Pure한 Machine Translation은 찾아보기 힘들었다. 여기서 제안된 Model은 Pure하게 Encoder-Decoder에서 Neural Network를 사용한 Neural Machine Translation으로 기존 Encoder-Decoder 모델의 성능을 능가하였으며 기존의 Phrase-based statistical translation만큼의 성능을 보여주었다.
우리가 생각해볼 수 있는 이 논문의 의의는 그동안 Statistical Translation이 주류를 이루고 있던 상황에서 새롭게 성능도 비슷한 Pure한 Neural Translation System을 제안하였다는 것과 Long Sentence에 대한 Encoder-Decoder 문제를 해결하기 위해서 현재 주류를 이루고 있는 Attention 개념의 Alignment를 도입했다는 것으로 볼 수 있다.