이전 Post에서는 Object detection에서는 Sliding window는 굉장히 좋은 방법이었지만 Computation cost가 큰 문제가 있었고 이를 해결하기 위해 CNN Implementation이 있다고 했다. 이를 적용한 Algorithm 중에는 굉장히 유명한 YOLO Algorithm이 있다.
YOLO
YOLO의 의미는 You look only once라는 것으로 이 의미처럼 YOLO Algorithm은 한 번의 계산(Forward propagation)만으로 Object Detection을 성공적으로 수행한다. 이렇게 한 번에 object detection을 할 수 있기 때문에 Real time object detection 분야에도 많이 사용되고 있다. YOLO Algorithm에서 사용하는 Data에는 기존의 Classification과는 달리 단순 labeling 뿐만 아니라 다음과 같이 object를 포함하는 box의 정보까지 담고 있다. 즉, Train 과정에서 Error는 class label뿐만 아니라 box의 정보까지 포함하게 된다.
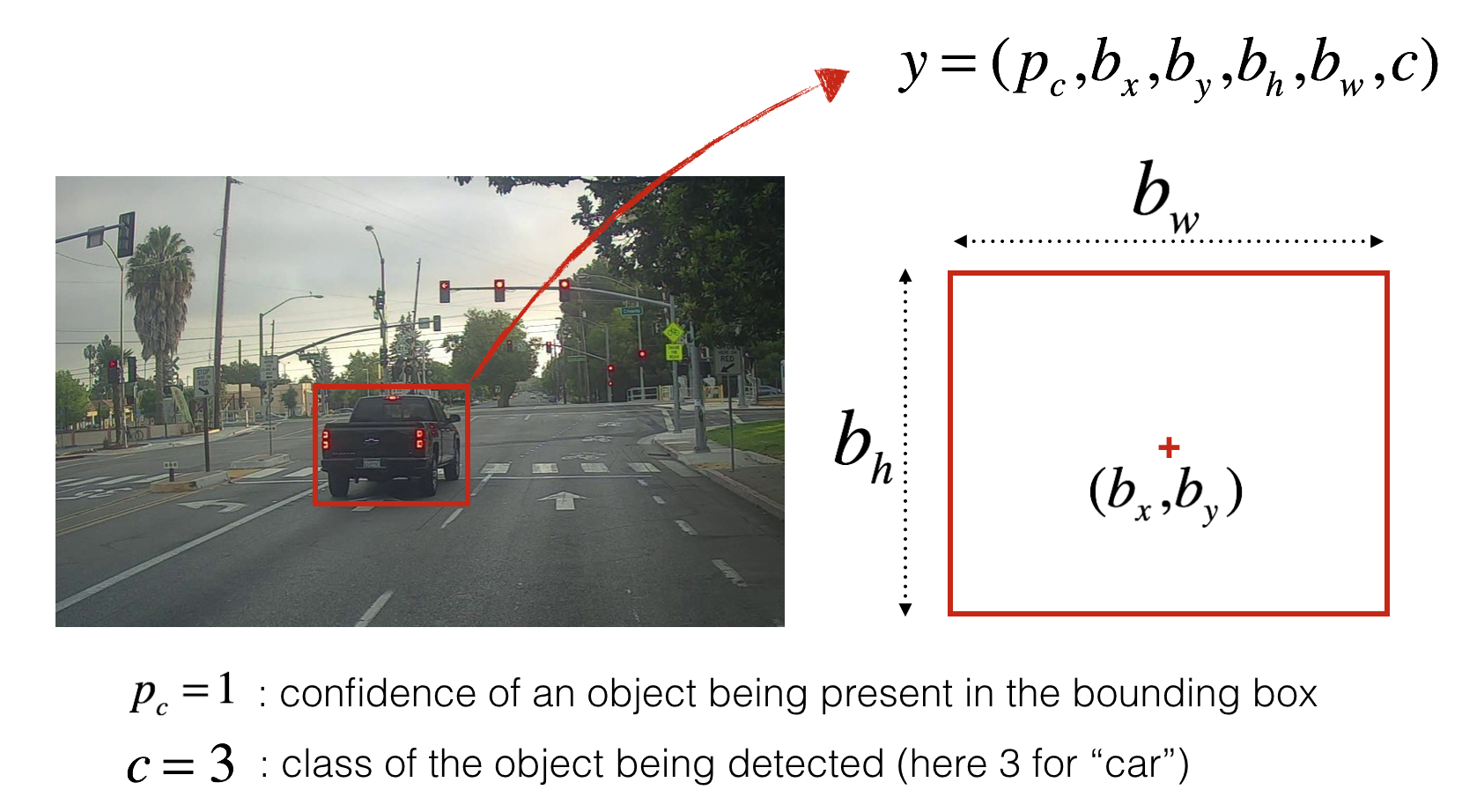
기본적인 구조는 앞에서 말한 것처럼 CNN Implementation of sliding window이며 추가적으로 정확도를 위해 Anchor box나 Non max suppression을 추가하게 된다. CNN의 결과물로 얻어지는 data는 각각의 window에 대한 계산값으로 하나하나를 grid cell로 생각해볼 수 있다. 각각의 grid cell에 object가 속하는지 안하는지의 여부는 object의 center / mid point가 grid cell에 속하는지 여부로 하며 하나의 cell에 여러개의 object가 속할 수도 있기 때문에 다양한 모양의 box 각각에 대해 계산을 진행한다. 여기서 언급된 다양한 모양의 box가 바로 anchor box로 예를 들면, 하나의 grid cell 에 속한 pedestrian과 car의 구분을 할 수 있게 해준다.(모양이 다르기 때문에)
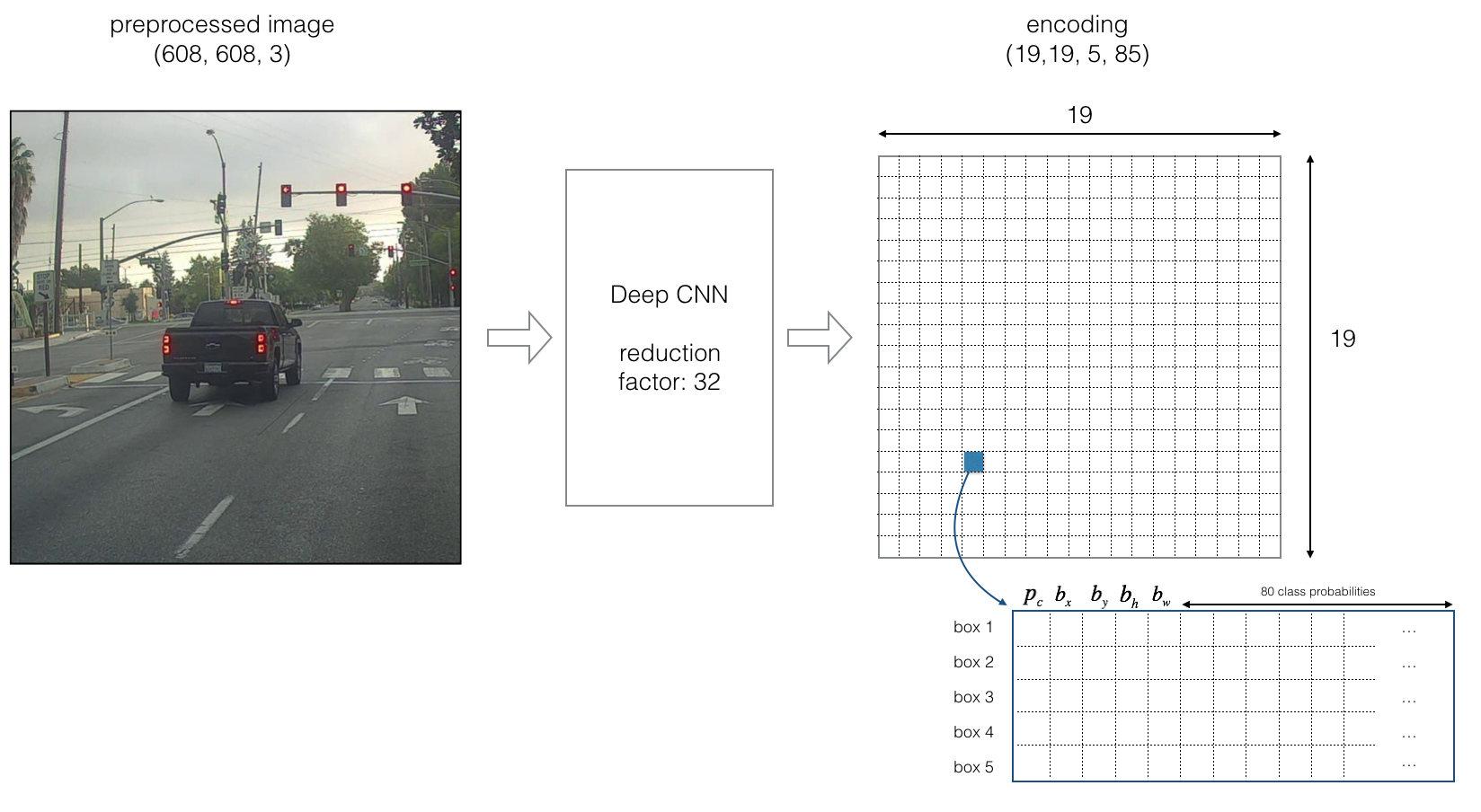
만약에 위의 그림처럼 19 x 19의 grid 하나하나에 4개의 anchor box가 있으며 총 20개의 80를 다루고 있다면 output of Deep CNN은 (19 x 19 x 5 x 85) shape이 된다. (grid cell x # of anchor box x (confidence of object present, box location(left top, right bottom), # of classes))
위의 방법을 통하여 각각의 grid cell 내의 anchor box에 속하는 object들의 정보를 얻었다면 일정 수준 이상의 confidence를 가지고 있는 object들만 골라내는filtering이 필요하다. 이를 위해서는 따로 Threshold를 정하며 비교는 confidence x class probs와 하게 된다.
이렇게 원하는 수준 이상의 object information을 얻었다면 다음으로 할 것은 하나의 Object에 대해 하나의 box만 적용하고 나머지는 제거하는 Non-max suppression(NMS) 과정이 필요하다. Key concept은 먼저 가장 score가 높은 box들을 뽑고 가장 score가 높은 box부터 나머지 box들과의 iou(intersection over union)을 비교하여 일정 수준 이상이면 제거하는 과정을 반복하는 것이다. 이 과정을 수행하게 되면 동일한 대상에 적용된 box는 최대한 제거할 수 있게 된다.
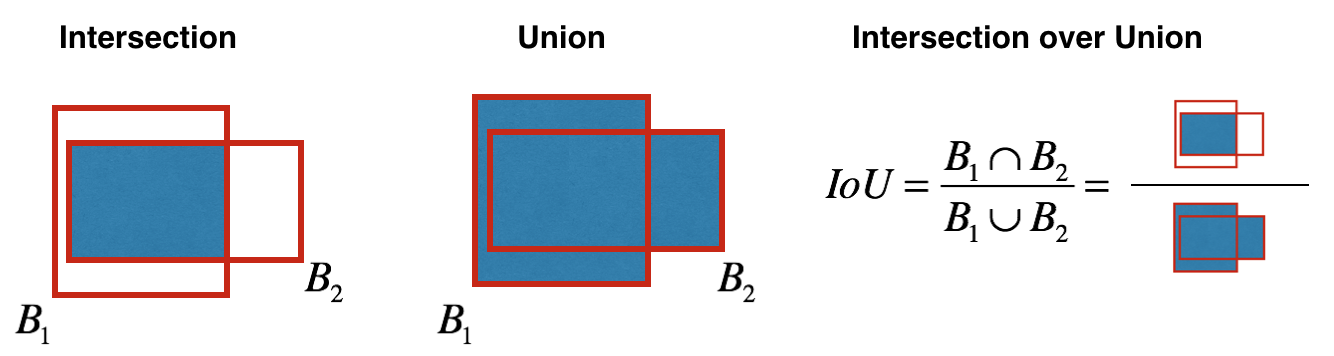
- NMS를 정리하면 다음과 같다.
- 가장 Score가 높은 box를 선택한다.
- 선택된 box와 나머지 box들간의 overlap 정도를 iou를 이용해 비교하여 일정 수준(iou_threshold) 이상이면 해당 box를 제거한다.
- 기존에 선택된 box를 제외한 나머지 box에 대해 남은 box가 없을 때까지 위의 과정을 반복한다.
이렇게 계산을 수행하면 우리가 원하는 Object detection을 성공적으로 수행할 수 있게 된다.
Question
- 어떻게 효과적으로 train data를 만들 수 있는지?
Todo
- Tensorflow에서 구현된 NMS말고 직접 NMS를 구현해보자(O)
- Pretrain된 data가 아니라 직접 train해보자
Ref
- Coursera 강의(Andrew Ng-deep Learning(CNN))
- Redmon et al., 2016 (https://arxiv.org/abs/1506.02640)
- Redmon and Farhadi, 2016 (https://arxiv.org/abs/1612.08242).