Inception Network Motivation
Inception Network는 그때 그때 적절한 filter size, pooling layer 등의 선택을 하는 것은 어렵기 때문에, 어느 특정한 filter size를 사용하는 것을 결정하는 것이 아니라 한꺼번에 다 사용하자는 아이디어를 가지고 있다. 즉, 2x2, 3x3, 5x5, max pooling등의 가능한 방법들을 따로따로 적용한 후에 그 결과물을 concatenate 함으로써 결과물을 얻자는 것인데, 다음과 같은 그림을 보면 쉽게 이해할 수 있다.
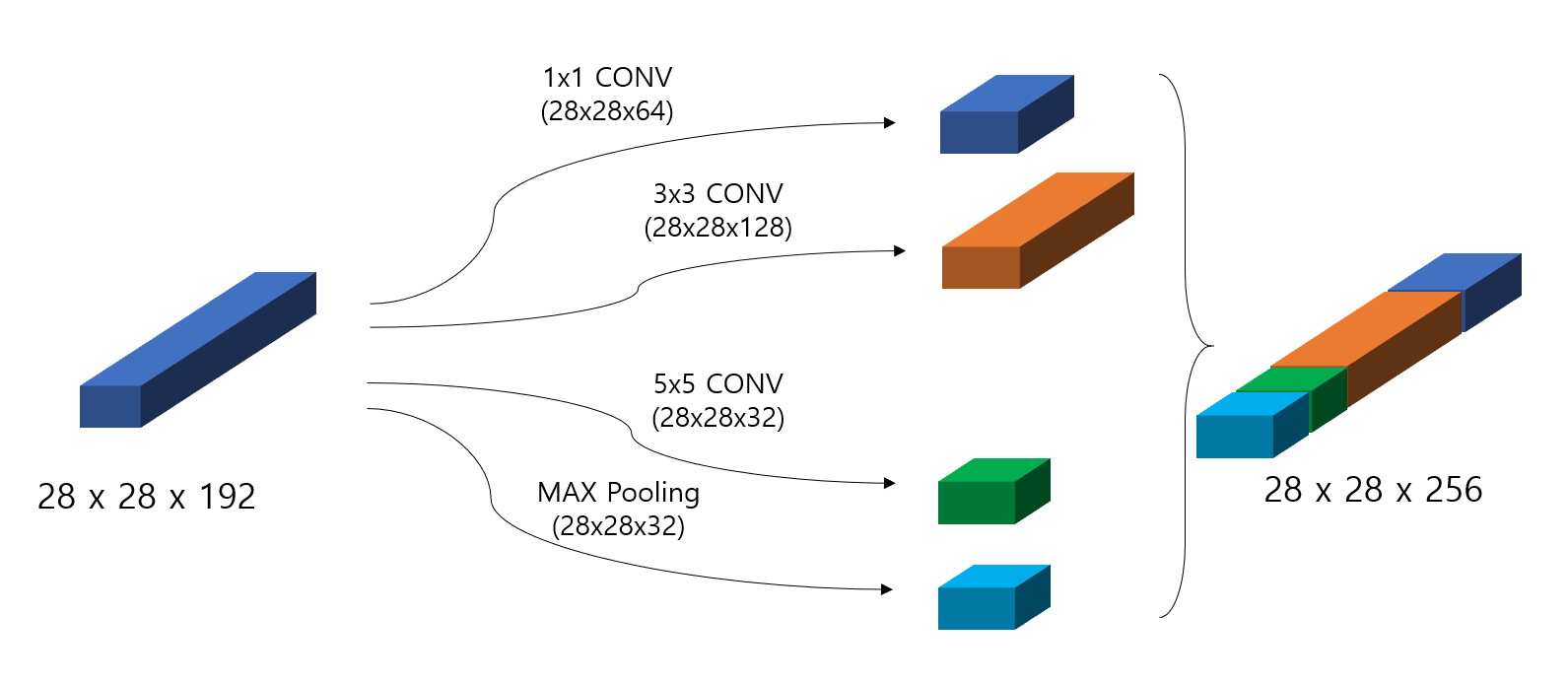
문제점
이런 방식을 택할 경우 특정한 filter size에 국한된 것이 아니라 다양성을 띄지만 문제는 역시 computational cost이다. 예를 들어 위의 그림에서 5x5 CONV(same, 32 channels)를 생각해보면 각각의 filter의 dimension은 5x5x192이며 Convolution을 진행하기 위해 전체 곱해야 하는 횟수는 28x28x32x5x5x192 ~ 120M이 된다. 즉, 전체를 계산하기에는 너무 많은 숫자가 된다.
해결책
너무 많은 Computational Cost를 줄이기 위해서는 channel의 갯수를 줄이는 것이 필수적이다. 이를 위해 제시된 것이 1x1 convolution이다. 1x1 convolution은 다른 filter size의 convolution을 진행하기 이전에 channel의 수를 줄이기 위해 적용하며 먼저 1x1 convolution 후 ReLu activation까지 적용시킨 후 본래의 5x5 convolution을 진행한다.
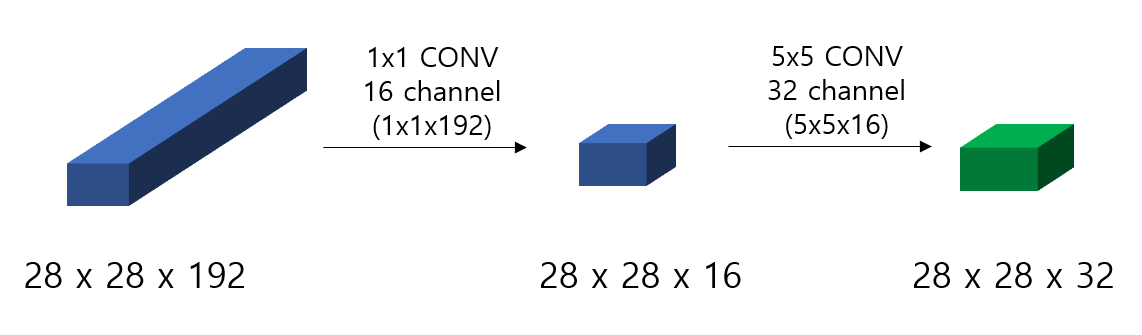
Inception Module
여러 종류의 filter size, pooling을 모두 적용시킨 후에 concatenate한다는 아이디어에 Computational cost를 줄이기 위한 1x1 convolution을 적용시킨 하나 하나의 Module을 Inception Module이라고 한다. 이전에 ResNet Module처럼 이러한 Module들이 여러개로 구성되어 더 깊은 Neural Network를 구성한다. 이러한 Block들을 반복하며 Layer의 갯수를 계속 늘려가기 때문에 “Going deeper with convolution”라는 논문의 이름이 아주 적절한 듯 하며 Inception도 영화에서 그랬던 것처럼 “We need to go deeper”의 의미에서 생각해보면 아주 딱 맞는다.
또한, Module들 중에 몇몇 모듈들에 대해서 마지막 Layer에서 결과를 얻는 것처럼 FC를 적용해서 중간 Hidden Layer의 결과물이 어떤지 확인할 수도 있다.
Question
- 위에서 제시된 1x1, 3x3, 5x5이외에 다른 filter size는 적용하면 어떻게 되나?
TODO
- Inception module에서 중간 중간 Hidden layer에서의 결과물을 비교해보기
Ref
- Coursera 강의(Andrew Ng-deep Learning(CNN))
- https://arxiv.org/pdf/1512.03385.pdf